背景
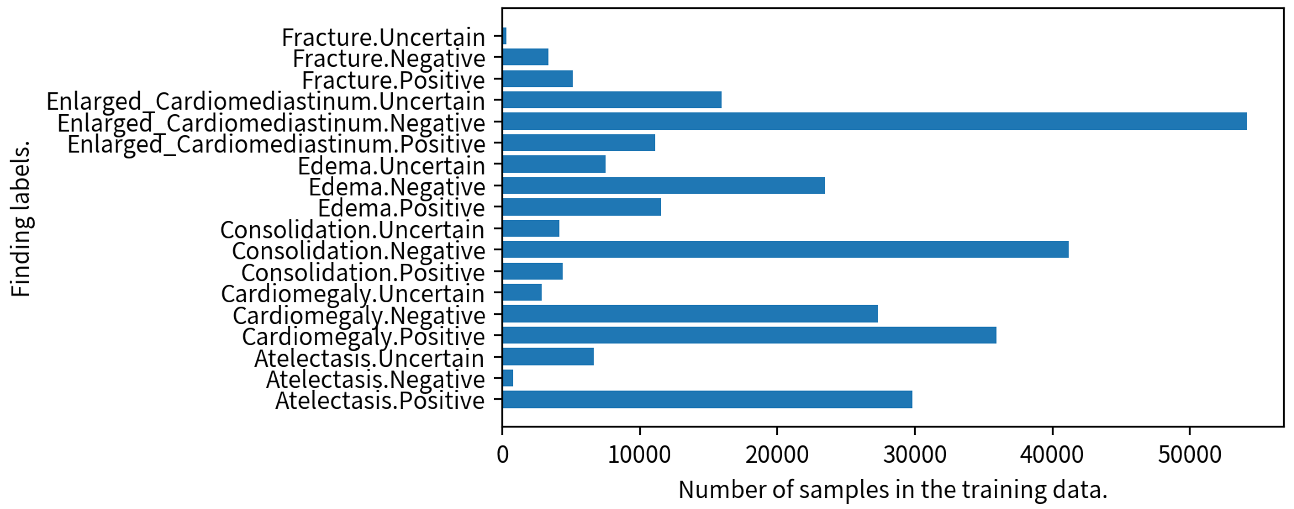
放射線科医はCT・MR等の画像検査を見て病状や病名を確認し、それらを読影レポートにまとめる必要がある。近年は検査件数の増加や撮影装置の高性能化に伴う撮影範囲の広がりを背景として、1人の放射線科医が扱わなければいけない画像の枚数が飛躍的に増えた。医用画像の所見から読影レポートを自動生成できれば、放射線科医の作業負担を軽減できる。機械学習の発展により、人間が日常的に使っている言語(自然言語)をコンピュータで扱うことができるようになってきた。高精度な読影レポート生成システムを学習させるためには、起こりうる性状が偏りなく含まれた良質な学習データが欠かせない。しかし、実際に収集できるデータは臨床的に起こりやすい性状と起こりにくい性状の不均衡性が大きく(図1)、起こりにくい性状を含むレポート生成は、既存の学習手法では困難である。
アプローチ
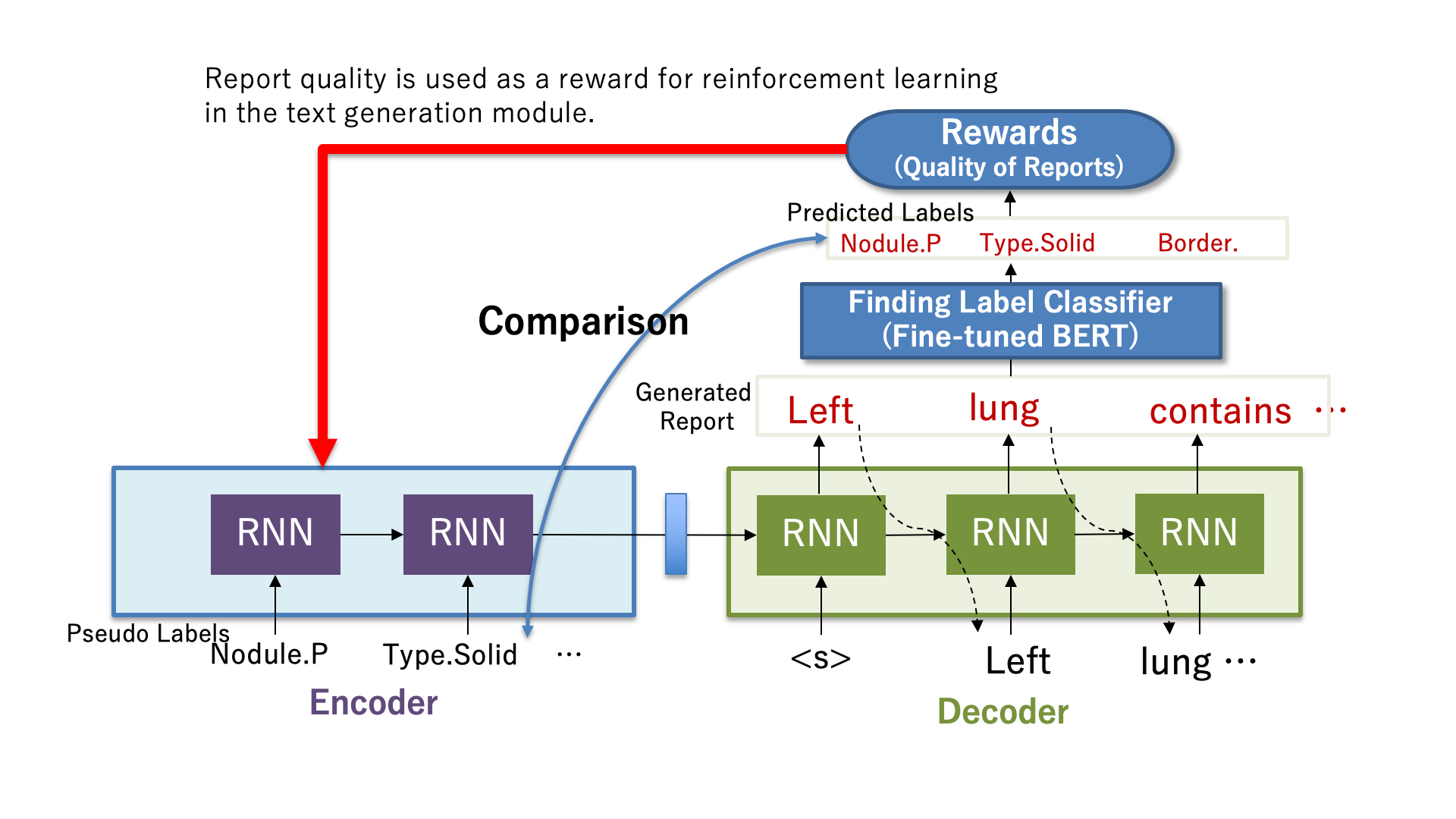
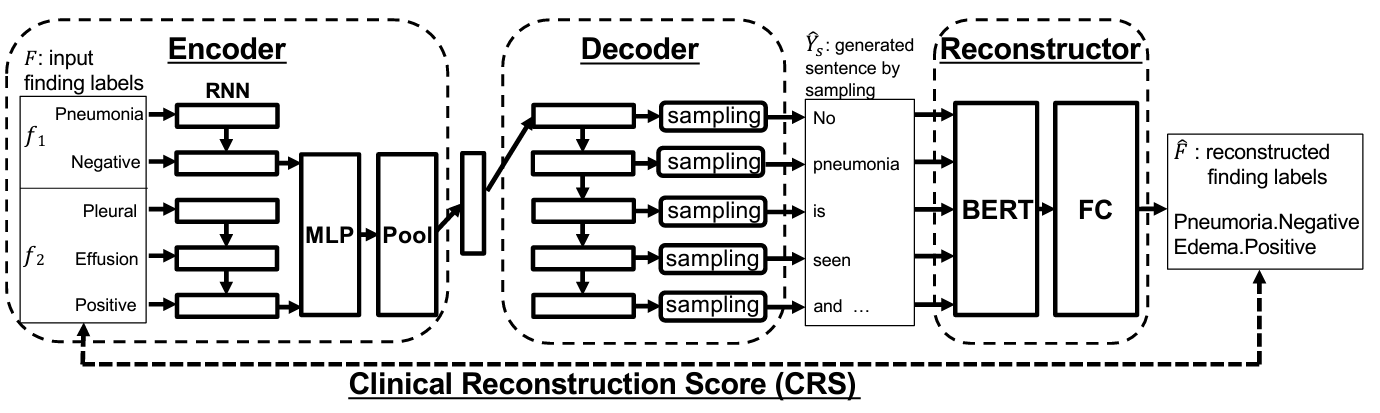
今回紹介する論文[1]では、レポートの適切性(生成所見文内に入力した性状が正しく反映されている度合い)を報酬とした強化学習の手法(図2)を提案している。学習データ中にない「疑似所見ラベル」を機械的に作成し、強化学習の追加学習データとして利用する。学習データ中で出現頻度の少ない性状を「疑似所見ラベル」により量増しして学習することで、出現頻度の少ない性状を含んだレポートも正しく生成できるようになる。日本語データ(肺結節CT)及び英語データ(胸部単純X線)での評価を実施し、日本語データでは適切性F値の 3.1pt改善、英語データでは適切性F値5.4ptの改善を確認できた。
まとめ
疑似所見ラベルを作成と適切性を報酬とした強化学習を組み合わせることで、出現頻度の低い性状ラベルを含む所見文の生成精度が向上した。本論文での評価は胸部画像を対象としていたが、他臓器でも学習データセット構築コストの低減と高精度な読影レポート生成の両立が期待できる。
DOI: 10.18653/v1/2020.findings-emnlp.202
ご注意:
本ページに記載された技術情報・論文内容は、弊社製品搭載技術とは異なる場合があります。
全ての技術は、必要な法規制認可を得た上で製品搭載を予定します。
製品搭載時の仕様および外観は本Webサイトの内容とは異なります。